# Introduction
In this post we learn about the basics of process analytics. This is part 1 of a series of posts in which we explore various topics surrounding process analytics.
A **business process** is a “collection of related and structured activities or tasks” that focus on providing a certain service or achieving certain goals in the context of a business environment.
**Business Process modelling** is a process of representing information flow, decision logic and business activities occurring in a typical business process. It can also be seen as ordering of work activities across time and place with clearly defined input and outputs representing a structure for a set of actions occurring in a predefined sequence.
Process analytic approaches allow organizations to support the practice of Business Process Management and continuous improvement by leveraging all process-related data to extract knowledge, improve process performance and support managerial-decision making across the organization. Process analytics enables firms to take a data-driven approach for identifying performance bottlenecks, reducing costs, extracting insights and optimizing the utilization of available resources.
In developing process analytic capabilities enable analytic-driven decision making and can support organizations in following ways:
* Assisting organizations in understanding process behaviour captured in process execution logs.
* Identification of performance bottlenecks, optimizing the utilization of resource allocation, and uncovering root-causes of undesired process behaviour/outcomes.
* Supporting process stakeholders and process users in the execution of processes by making accurate process behaviour forecasts for running cases
* Providing decision support to process users and knowledge workers
* Supporting the practice of risk management by assisting in early identification and possible mitigation of undesired effects
Understanding the properties of ‘current deployed process’ (whose execution trace is available), is critical to knowing whether it is worth investing in improvements, where performance problems exist, and how much variation there is in the process across the instances and what are the root-causes. In order to develop process analytic capabilities for Invertigro, it is crucial to collect relevant data in a manner which captures the ordering of activities (events), associated resources and their associated outcomes . We can also view this past process execution data as representing either positive (value-adding) outcomes or negative (non-optimal) outcomes This Process execution data once collected will contain hidden insights and actionable knowledge that are of considerable business value. Implementing a strategy that will allow InvertiGro to develop process analytics capabilities would also involve experimenting with various methods, tools and techniques. This will allow us as an organization to understand the behaviour of our processes, monitor currently running process instances, predict the future behavior of those instances and provide better support for operational decision-making across the organization. Overall, Process analytics can also be viewed as an organizational capability that will enable InvertiGro to stay competitive by better understanding its internal processes and identifying areas of improvement.
Organisations can drive business value by:
* Mapping their processes (both manually and leveraging process discovery tools). i.e mapping their strategy-decision-data landscape, to identify low-hanging fruit for decision automation
* Putting in place a process analytics solution for the critical decisions identified in step 2, using a combination of off-the-shelf tools
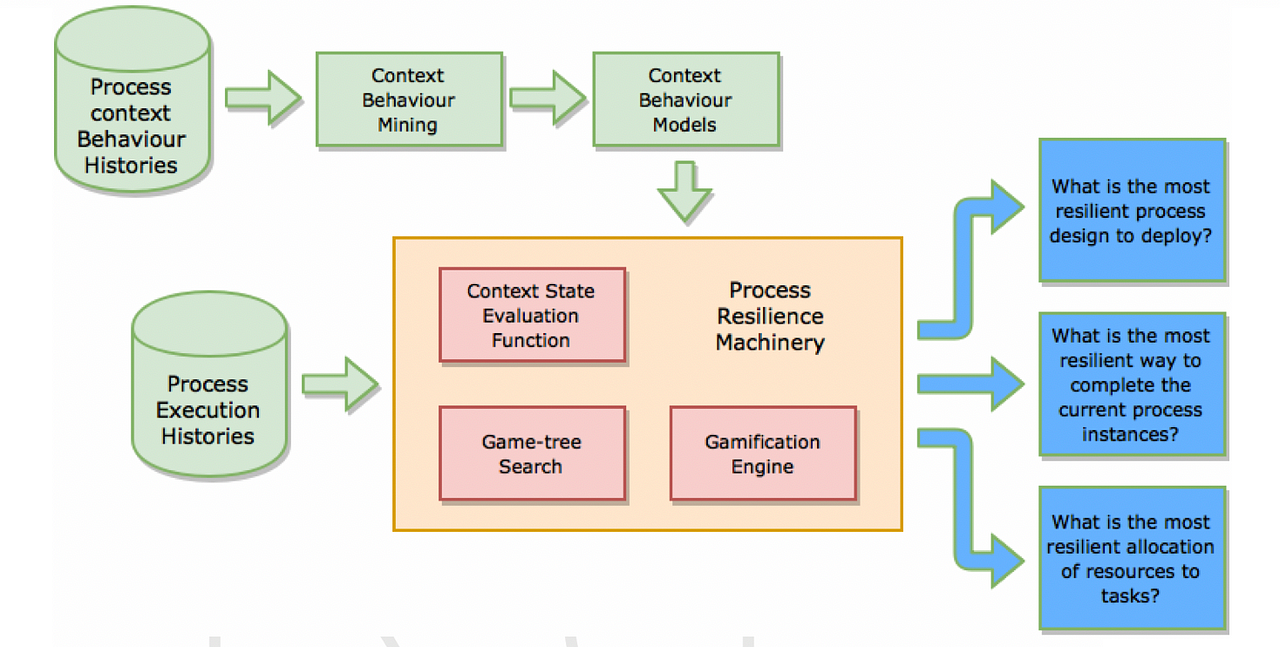
* Adding flexibility/resilience to process execution machinery (to cope with Covid like events)
* Putting in place an over-arching process governance framework.
**Types of Relevant Organisational Data:**
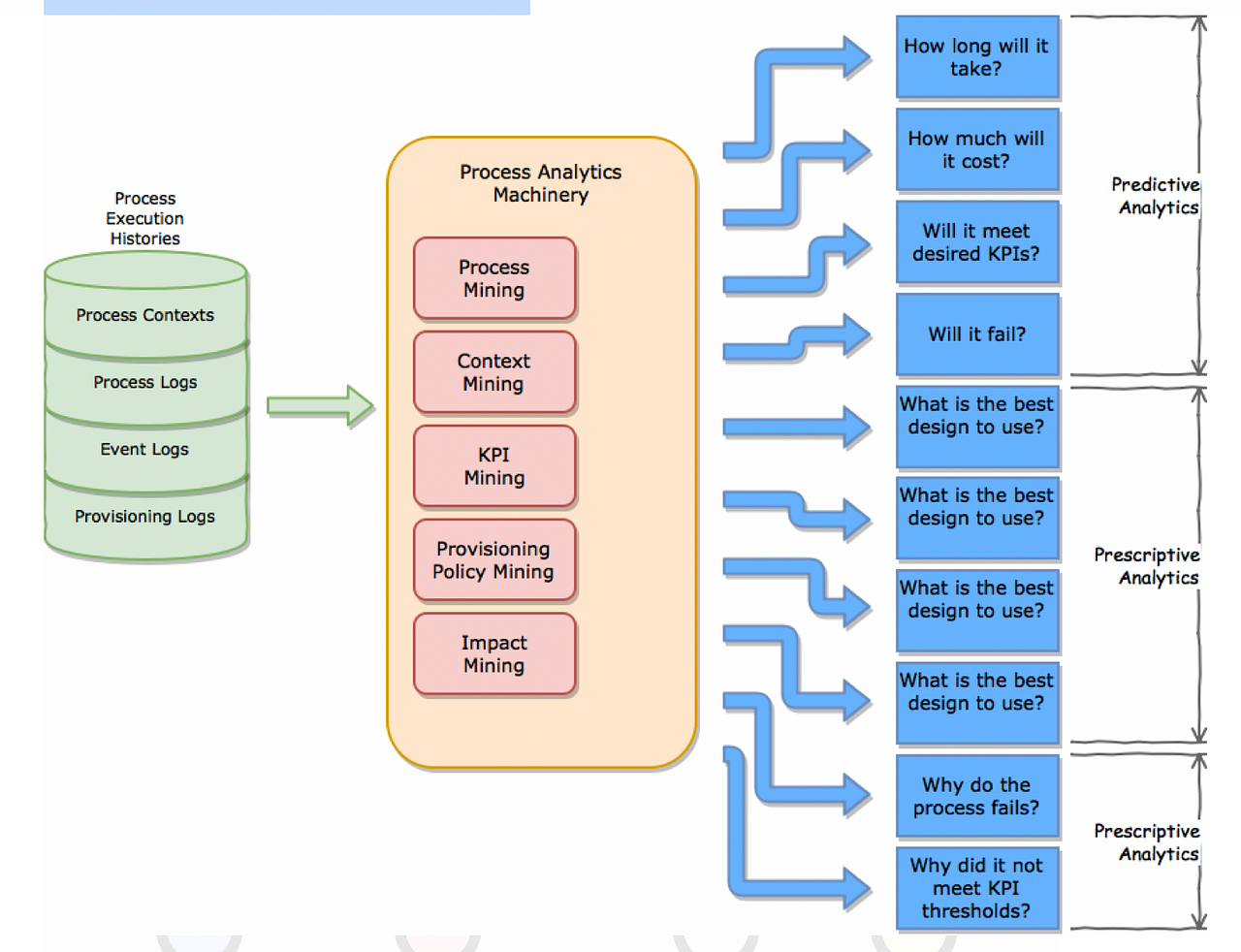
* **Process Logs:** These record process tasks performed, together with a time-stamp, and an indication of the resource (an employee, a machine etc.) used to perform the task.
* **Event Logs:** These record critical events (such as state transitions of objects impacted by a process) together with the time when these occurred.
* **Provisioning Logs:** These record what people or machines were deployed to perform process tasks in greater detail;.
* **Process contexts:** These record a description of a process’ operating environment. The time-stamps associated with a process can used to access sales data current at that time, financial market sentiment (via publicly available data) or the political/economic context (via open news sources).
Process mining techniques can leverage this execution data to mine actionable knowledge, discover insights about performance bottlenecks, frequent defects, their root causes and other sources of inefficiencies.
Given process logs as input, the process analytic machinery developed by this project will generate predictive (what is the likely outcome?), prescriptive (what should be done next?) and diagnostic (why did things turn out the way they did?) insights to support (and provide an evidence base for) farming decisions.
The ***process analytics machinery*** includes the following 5 components:
* **Process mining:** This is used to learn process designs from past process logs. Recently, process mining emerged as a new scientific discipline on the interface between process models and event data. On the one hand, conventional Business Process Management (BPM) and Workflow Management (WfM) approaches and tools are mostly model-driven with little consideration for event data. On the other hand, Data Mining (DM), Business Intelligence (BI), and Machine Learning (ML) focus on data without considering end-to-end process models. Process mining aims to bridge the gap between BPM and WfM on the one hand and DM, BI, and ML on the other hand. Here, the challenge is to turn torrents of event data (“Big Data”) into valuable insights related to process performance and compliance.
* **Context mining:** This module mines the context associated with a process or process task along the lines described above.
* **KPI mining:** This module is used to learn the expected KPI (or Quality-of-Service) performance of a process or process task, given that there is often considerable variability in these measures.
* **Provisioning policy mining:** This module helps learn the provisioning policies (rules for allocating resources to tasks) that are associated with the best process performance.
* **Impact mining:** This module is used to mine process impact (i.e., the changes to the environment achieved by the execution of a process) — usually from process logs and event logs.
#### Process Conformance and Enhancement:
The second type of process mining is conformance, used to check process conformance where we compare an existing process model with an event log of same process model. The idea here is to check if the actual process model(as recorded in the event log) aligns with the initially designed and deployed process model. The third type of process mining is enhancement, which is used to enhance or extend an existing process model by using information recorded in the event log. For example by using timestamps and frequencies, we can identify bottlenecks, diagnose performance related problems and analyze throughput times. This helps us explore different process redesign and control various strategies.
The key ***predictive analytics insights*** concern the time, cost and other KPIs of process designs that are about to be executed or currently executing process instances. These can also be used to predict process failure (or exceptional terminations).
* The key ***prescriptive analytics insights*** are used to decide what process design to use, how to complete (i.e., a suffix of a task sequence) a partially completed process instance, the best resources to allocate to process tasks (either for a process design about to be executed or for a partially completed process instance) and the best provisioning policies.
* *Diagnostic analytics* can help explain why a process failed, or why it failed to meet KPI targets.
\[1]
[PREVIOUS ISSUE**Getting started with Data Engineering in Spark**](https://blog.asjadk.com/data-engineering-with-spark/)[NEXT ISSUE ](https://blog.asjadk.com/improving-process-efficincy-with-process-mining/)
---
# Agent Instructions: Querying This Documentation
If you need additional information that is not directly available in this page, you can query the documentation dynamically by asking a question.
Perform an HTTP GET request on the current page URL with the `ask` query parameter:
```
GET https://hitchhikerguide.gitbook.io/process-analytics/introduction.md?ask=
```
The question should be specific, self-contained, and written in natural language.
The response will contain a direct answer to the question and relevant excerpts and sources from the documentation.
Use this mechanism when the answer is not explicitly present in the current page, you need clarification or additional context, or you want to retrieve related documentation sections.