


value is v(s) is calculated by doing a 1 step look ahead - once we have the values we can act greedily in our policy (Estimate and Act greedily)


Value of the room is given by one step lookahead where we consider all the actions we(agent) might take and the probabilitiy of those action leading to certain states(randomness by enviornment) - we look at the values of successor states and we back that all up - sum it all up (weighted by the probabilities) - the expectation of Bellman Expectation equation - Vector form


Values given by the value function applied to the random policy give us a better policy when we take those values and act greedily
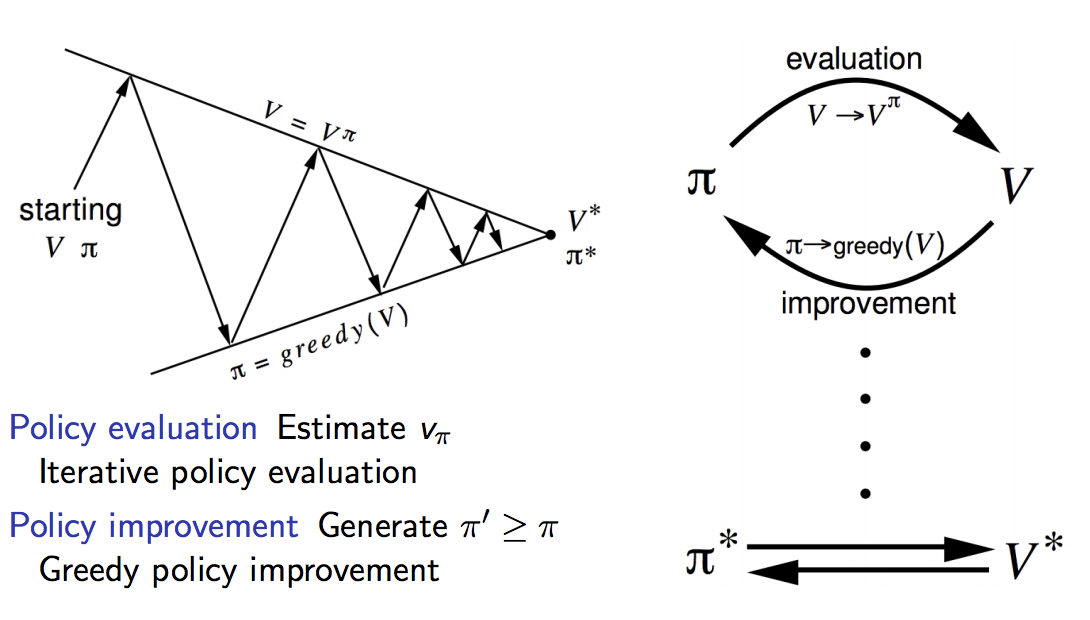
This process of evaluation and improvement will eventually lead to the optimal policy


we define acting greedily as pick actions in a way that gives us the maximum action value